使用ollama本地搭建deepseek
使用ollama本地搭建deepseek
1、准备工作
1、电脑配置:确保你的电脑具备一定的硬件性能,至少拥有 8GB 及以上的运行内存和足够的硬盘空间。如果有英伟达显卡,部署和运行会更加流畅。
2、下载 ollama:你可以在 ollama 的官方网站(https://ollama.ai/)上找到对应你操作系统(Windows、MacOS 或 Linux)的安装包,下载并安装。
简单来说,如果你的电脑配置满足最低要求(如8GB内存以上),就可以通过工具(如Ollama)轻松实现本地部署DeepSeek。
实践是检验真理的唯一标准,话不多说,开干。
2、本地电脑部署DeepSeek大模型具体步骤
1、安装ollama
1、本地部署首先要安装ollama,ollama 是一个用于在本地运行大语言模型的工具,它能让你在自己的电脑上轻松部署和使用各类模型。你可以把它理解为,一个装AI的盒子,把AI装在盒子里,方便管理。
访问ollama下载地址:https://ollama.com/download
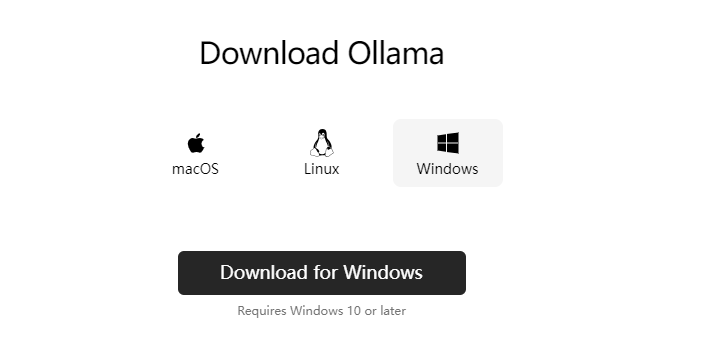
根据自己的电脑类型,选择不同版本。
2、接下来以Windows为例,下载好安装后,双击安装。(傻瓜式安装即可)
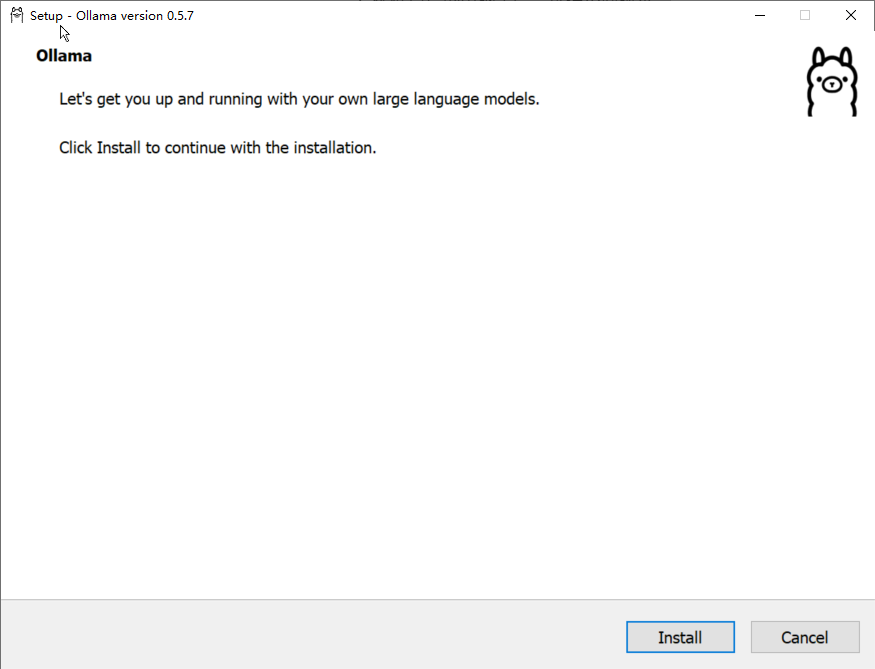
安装完成后,ollama会在后台运行,任务栏会出现一个类似羊驼的图标。
2、选择要安装的模型
1、访问https://ollama.com/search,选择要安装的模型
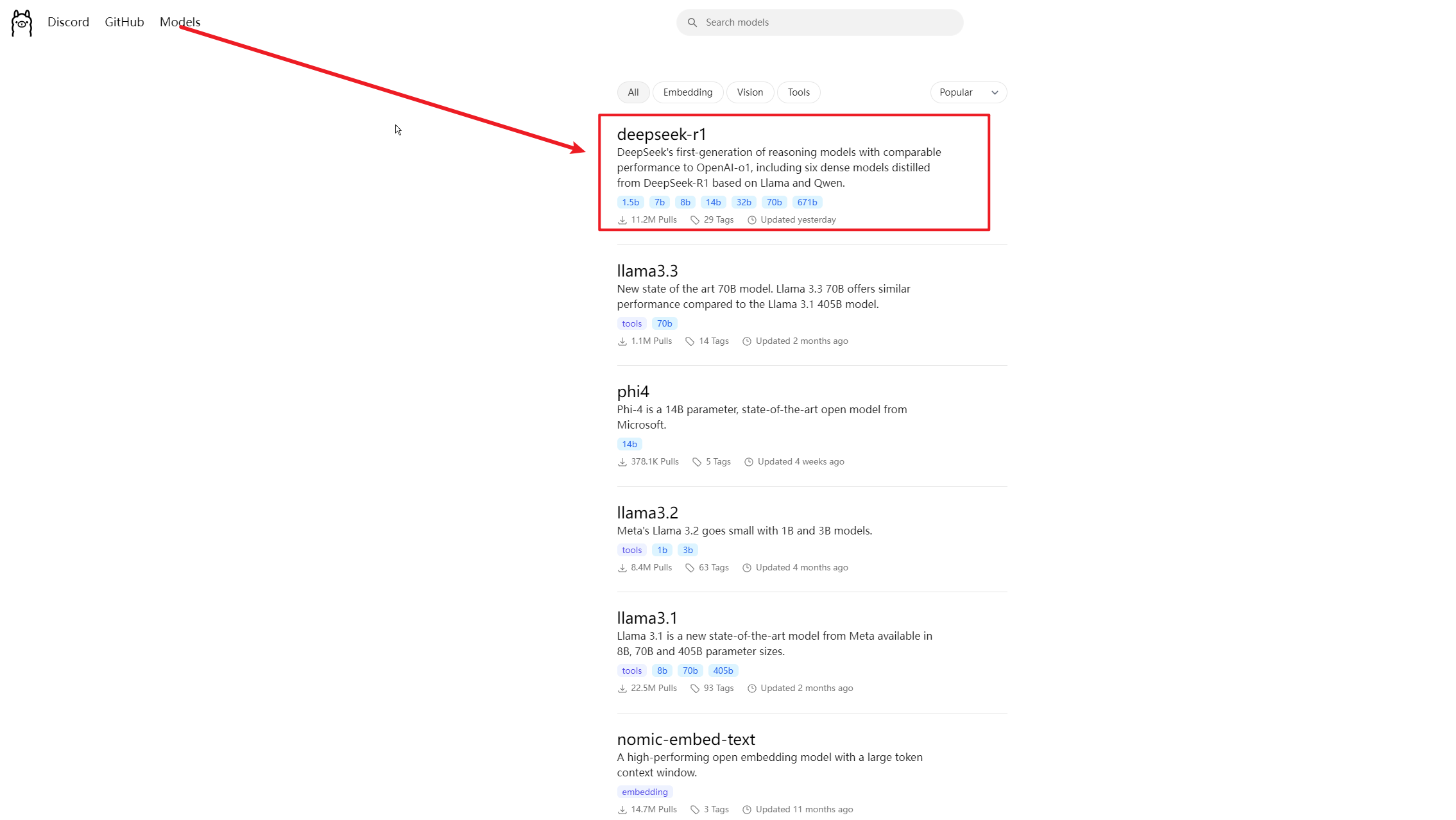
2、点击选择deepseek-r1,进入模型参数界面
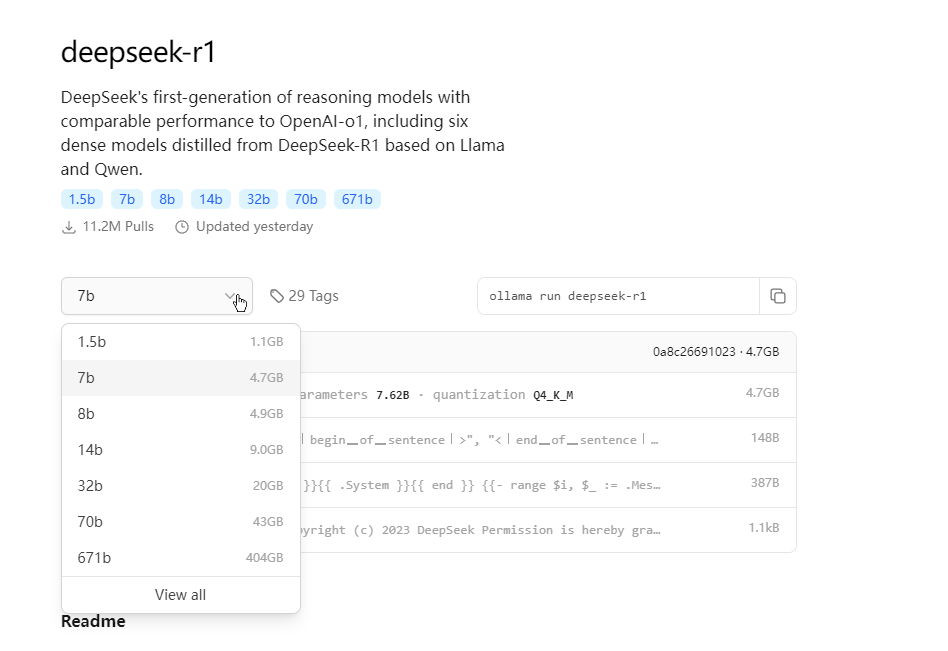
这里的数字越大,参数越多,性能越强,所需要的配置也就越高,1.5b代表模型具备15亿参数。
例如,若要运行14b参数模型,需要大约11.5G显存。也就是你的电脑显卡最好要达到16G。
若个人学习用途,一般建议安装最小的1.5b版本即可。大多数的个人电脑配置都能跑的起来。具体大家可以根据自己的电脑性能选择。
3、以1.5b参数为例,选择1.5b参数后,复制红框中的命令ollama run deepseek-r1:1.5b。
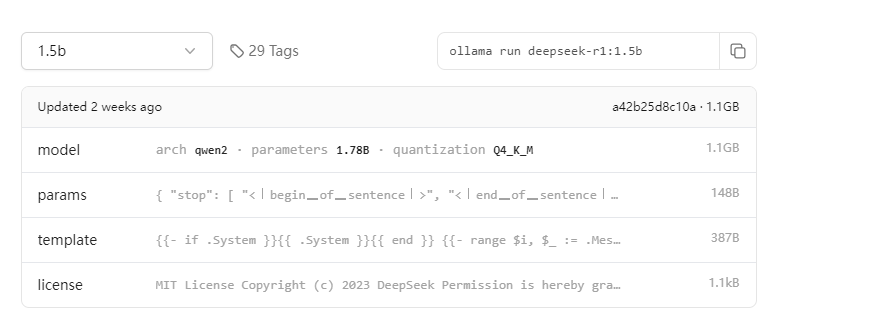
详细地址: https://ollama.com/library/deepseek-r1:1.5b
3、安装模型
1、打开命令行,在命令行中输入:ollama run deepseek-r1:1.5b
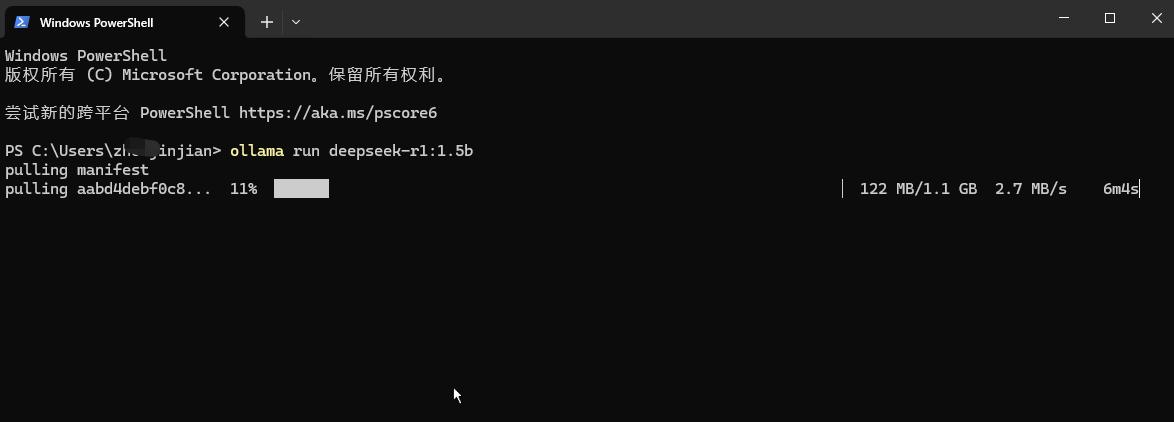
2、下载成功后,就可以与模型对话啦。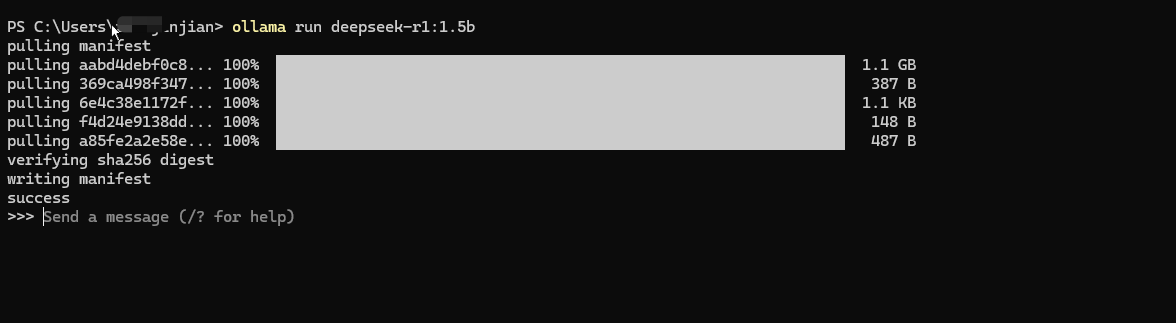
此时大模型安装在你的电脑上,就算断网也可以继续用,再也不用担心数据泄露了。
4、使用模型
安装好模型后,此时我们可以通过命令行的方式,在命令行中发送消息来与DeepSeek 大模型对话。
1、例如我的第一个问题是:”世界上是先有鸡还是先有蛋?”
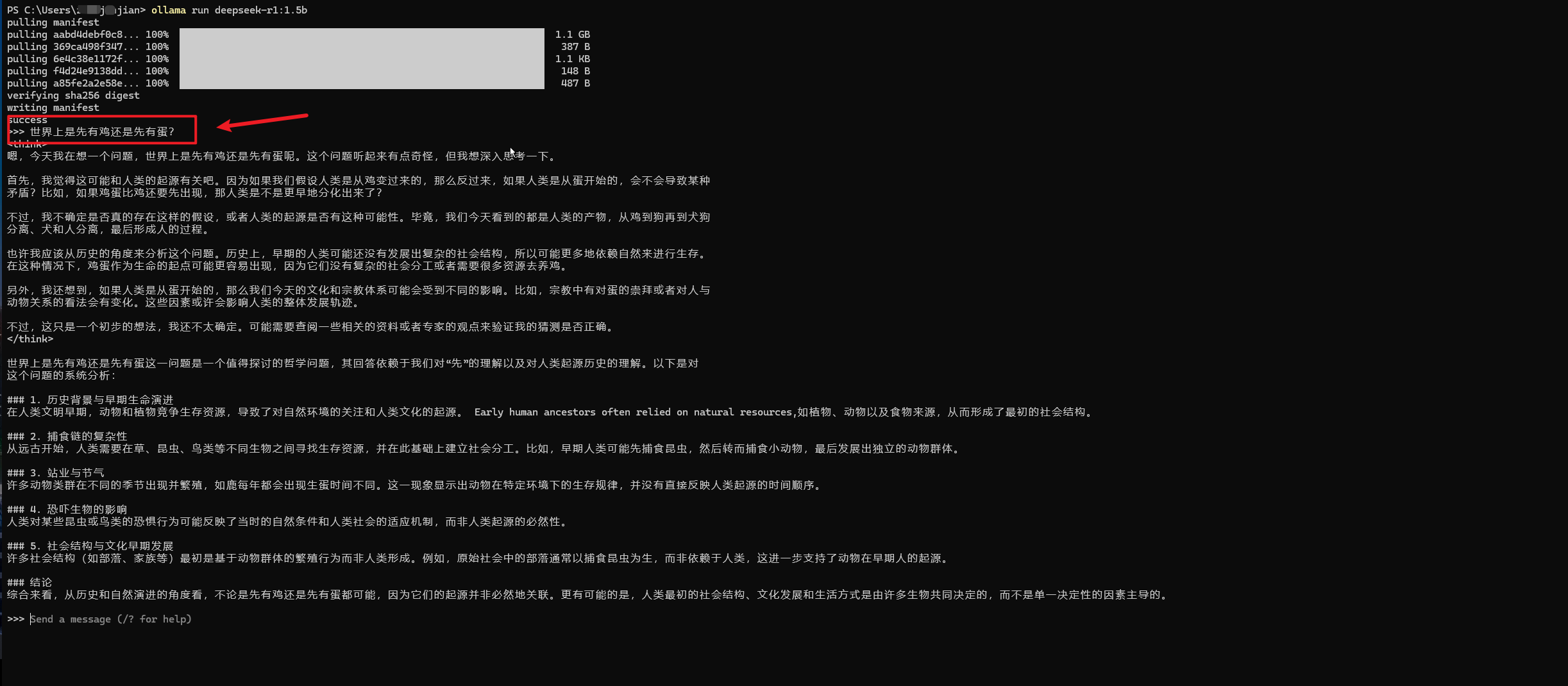
对于这个问题,回答的还可以,果然是推理型模型,思考的过程也给我们列出来了。
2、我的第二个问题是:”你是如何看待DeepSeek爆火的原因“?
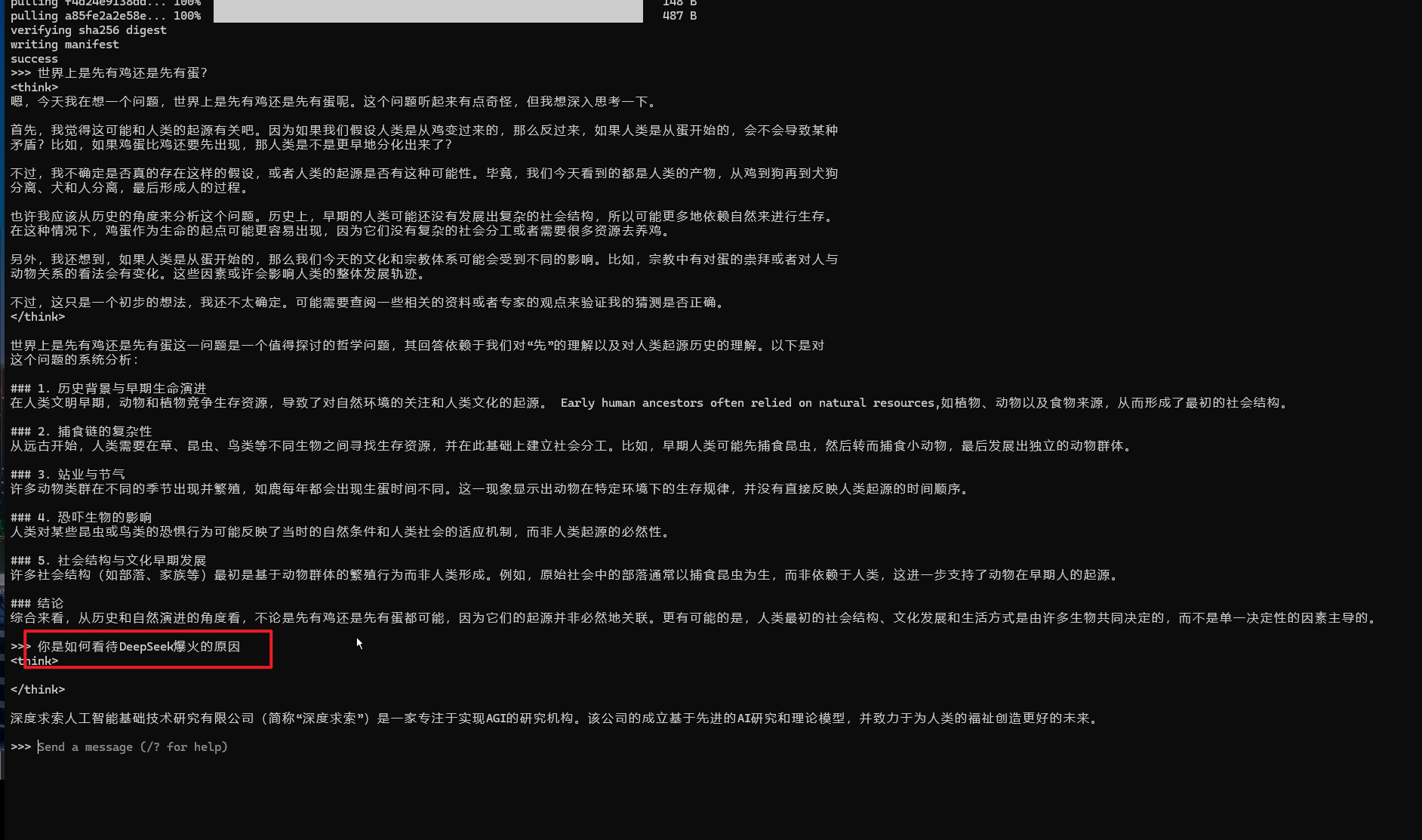
这个问题,回答的就太过于敷衍了,直接将DeepSeek的公司背书给出来了,当然也可以理解,毕竟DeepSeek的投喂数据都是几个月前的,那时,它还并没有爆火出圈,而且我们下载的还是最小阉割版模型。
3、这里还有一个问题,当你关闭电脑后,下次若再想使用本地模型时,只需要启动了ollama,
同时打开命令行界面,输入ollama run deepseek-r1:1.5b 即可。因为你之前已经下载过,这次无需下载,可以直接和模型聊天。
5、为本地模型搭建UI界面
1、使用命令行方式来和模型对话,对于不会编程的小伙伴来说,太难受了。不过没关系,我们有很多方案可以为你的本地模型搭建UI界面,比如Open-WebUI、Chatbox AI等。
2、这里我们以ChatBox AI为例,访问:https://chatboxai.app/zh

选择对应的版本,下载安装。
3、选择使用自己的 API Key 或者本地模型:
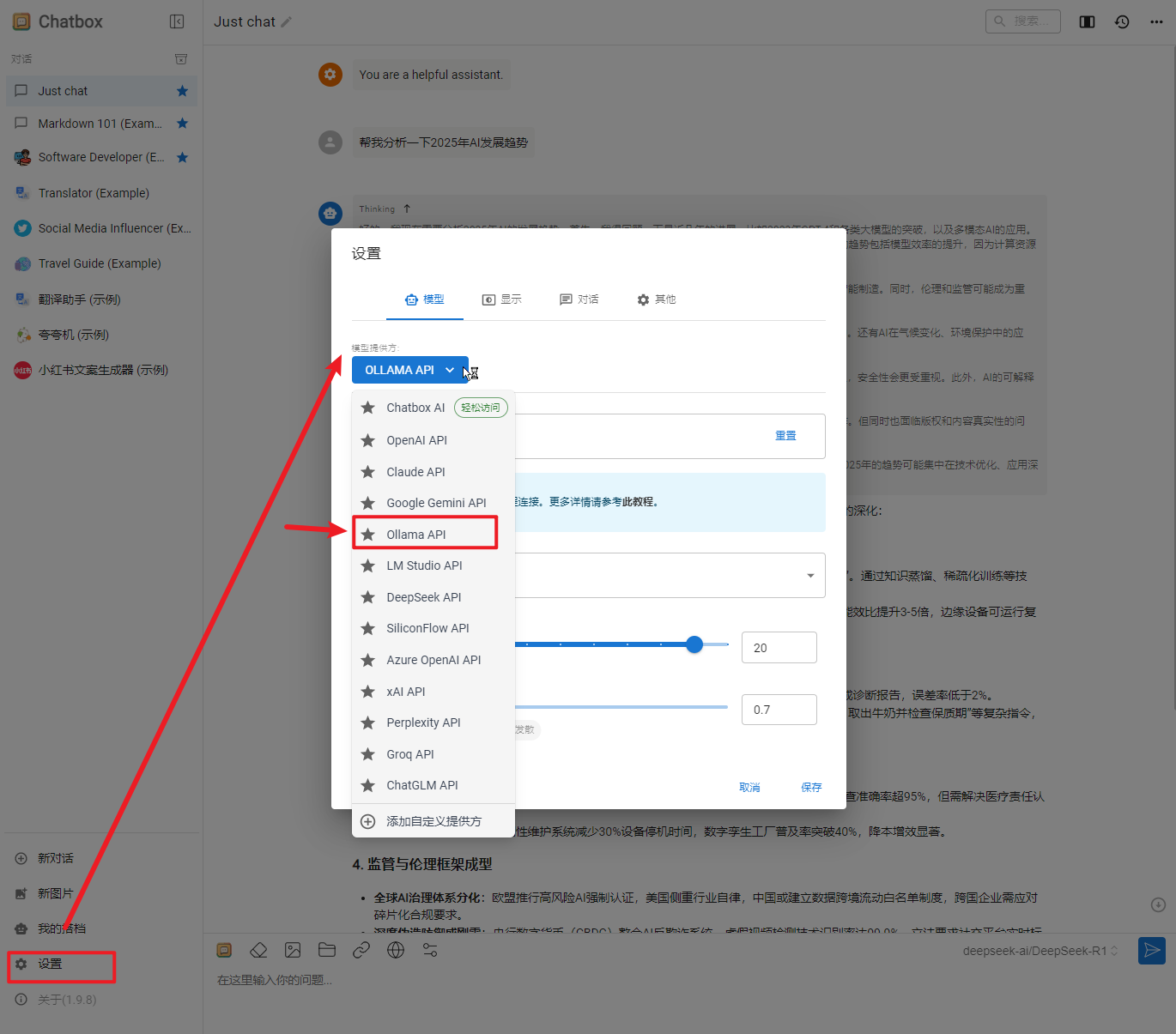
4、选择本地跑的 deepseek-r1:1.5b模型:
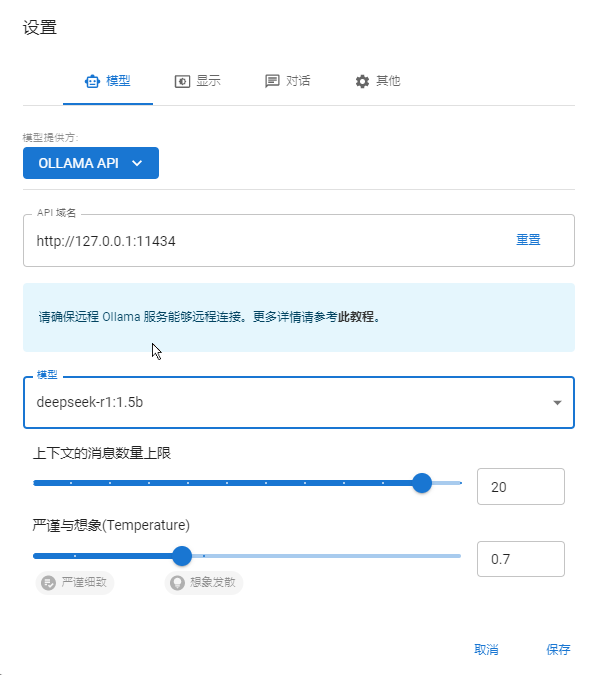
Ollama 默认使用 端口11434 提供本地服务。当你在本地运行 Ollama 时,可以通过以下地址访问其 API 服务:http://localhost:11434
如果你需要更改默认端口,可以通过设置环境变量 OLLAMA_HOST 来指定新的端口。
5、在ChatBox对话框中,输入:”先有鸡还是先有蛋“,即可调用本地模型,生成答案
