
在Cursor中开发Java项目 -- 开发环境常用插件
在Cursor中开发Java项目–业务系统开发
一、Cursor Tab
cursor tab 是一个集代码自动提示、自然语言指令的编程助手
代码自动提示和完成跟以前的 copilot 依然比较相似,就是在光标末尾自动提示接下来可能有用的代码,不过 cursor 对于这种支持更进一步,其还支持:
多行编辑
智能重写
光标预测
1. 自动提示
自动提示会根据光标停留处字符的上下文,给出一定的自动推理,
给出注释:“根据给定的区域列表,找出没有子级的区域”,很快 cursor 就给出了对应的提示,虽然可能我们还没来得及完整阐述具体的需求,不过这种及时快速反馈无疑一定程度上能加速开发,减轻负担

2. 智能重写
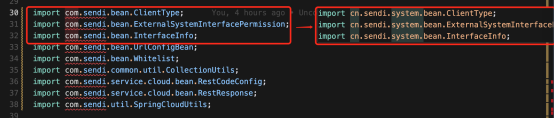
以下场景是从另一个项目中拷贝过来的代码,其中的 import 包位置发生了变化,此处 cursor 根据之前的修改历史,推断出此处应该要做右边这种修改,给出了提示,按下 tab 键即可快速完成修改。
以下的场景是:需要将百度上搜索到的广州行政区域街道数据入库到数据库中,由于数据量不多,直接改成一条insert sql语句,原本是单列的街道数据,匹配数据库表(id, region, create_time, update_time, parent_id) 字段列,如下:
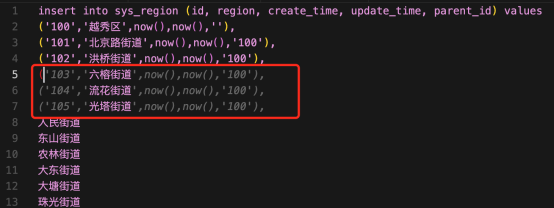
手动写完一两行value值之后,自动推断出来后面街道行对应的值,因此一直按下 tab 键,快速改完了后面的100多行街道的记录,尤其是区级、街道级这种上下级行政区域之间需要填充 parent_id 字段值,它也能准确识别需求
以往这种场景虽然靠着vscode多列编辑也基本能完成,不过相对麻烦一些,在cursor中,就轻松很多
3. 多行编辑
相邻多行代码比较相似时,修改其中一行,相邻的若干行会被自动提示相关的修改建议,按下 tab 键可以快速完成修改
4. 光标预测
想要实现光标自动预测,需要打开设置开关,位于右下角:Cursor Tab -> Cursor Prediction: enabled
像下面修改了一些地方的代码之后,会自动关联出一些其他相似修改的位置,此时会出现一个 “->tab” 的图标,按下 tab 键光标会自动定位到对应行,此时会出现相关修改建议,再按一下 tab,完成修改


5. 自然语言指令
5.1. 代码修改:
这个方法存在一定的bug,我们先来看看让 AI大模型给我们解释理解一下代码逻辑
光标停留在在代码编辑框内时,按下 cmd / command + k,输入以下指令,
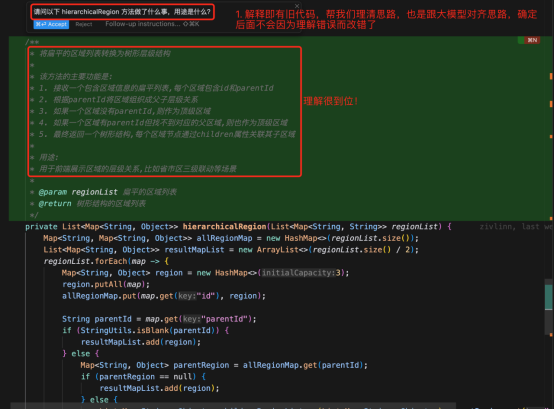
指令:“请问以下 hierarchicalRegion 方法做了什么事,用途是什么?”
光标停留在在代码编辑框内时,按下 cmd / command + k,输入以下指令,
指令:“regionList中的__部分区域存在父级区域,得到的结果仍把这部分区域当成了顶级区域,哪里有问题,如何修改__?”
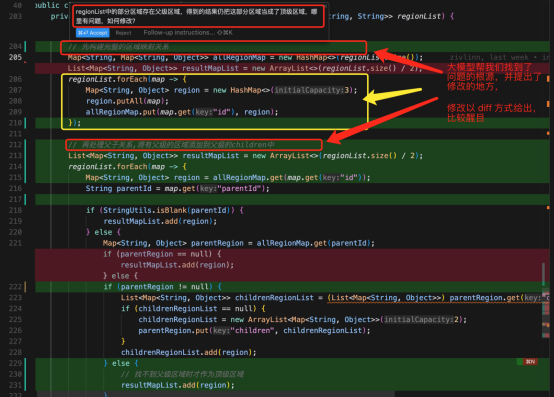
AI大模型发现了代码中存在瑕疵,即在判断当前区域是否存在父级区域前,需要有一个map存有所有的区域ID到区域的关系映射,然后才能从中判断某个父级区域是否存在,这是代码编写过程中产生的纰漏。
总结一下思路:
代码解释(开发者跟大模型之间__对齐思路__):保证大模型对代码意图的理解跟我们预期一致
表达问题:向大模型表达需要分析的问题,或者需要实现的目的
执行修改
检查
迭代(如果问题依旧存在,继续用自然语言反馈)
以下是另一个修改代码的示例:
光标停留在在代码编辑框内时,按下 cmd / command + k,输入以下指令,
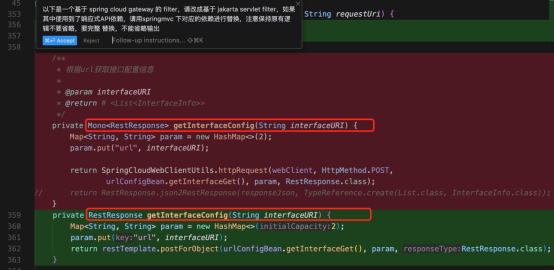
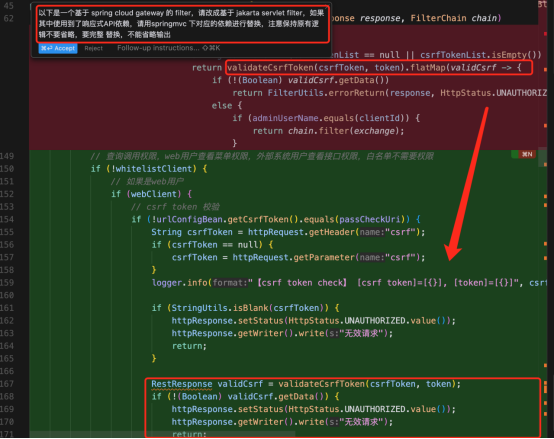
指令:“以下是一个基于 spring cloud gateway 的 filter,请改成基于 jakarta servlet filter,如果其中使用到了响应式API依赖,请用springmvc 下对应的依赖进行替换,注意保持原有逻辑不要省略,要完整替换,不能省略输出”
3.2. 终端命令
当你想不起某个命令该如何写的时候,光标停留在在终端处时,按下 cmd / command + k,输入以下指令,可以快速得到回答
指令:“需要导出maven依赖到 target/dependencies 目录下”


二、Composor / chat
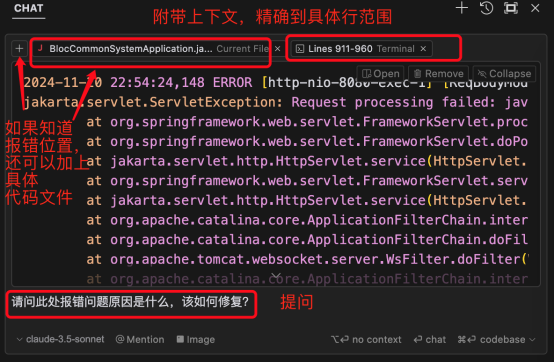
Composor 是一个对话式交互的编程助手,可以对话提问时灵活指定提问的上下文相关信息,比如 文档、代码、命令行执行日志,如果文档较大可以精确行范围,只要是文字形式的材料都适用
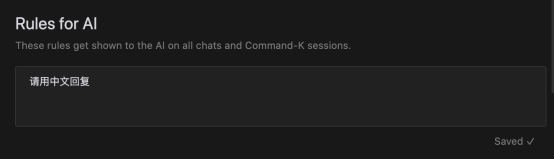
使用前,可以打开 cursor 设置对对话提示词设置系统规则,比如要求用中文进行回复,避免阅读大量英文回复
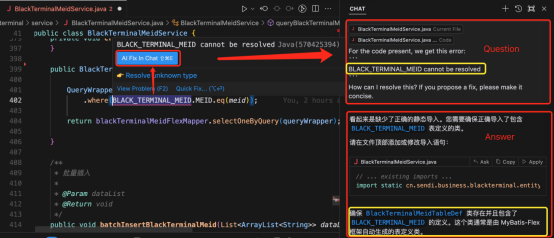
1. AI Fix:
在ide编辑器窗口编辑代码时遇到语法错误,鼠标悬浮于红线附近,会自动提示 AI Fix
点击 AI Fix in Chat 之后,报错会在 chat 对话栏向大模型发起提问,寻找解决办法
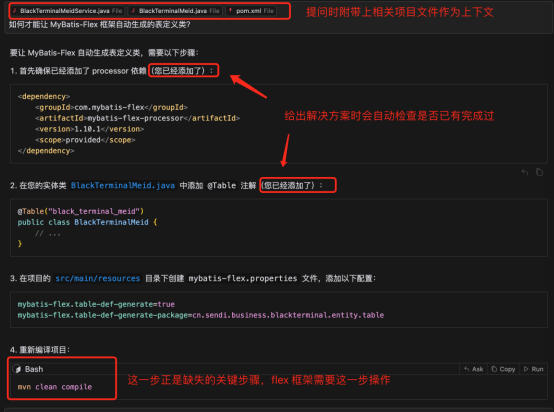
对于答案中如有不清晰的部分,进一步提问
 s
s
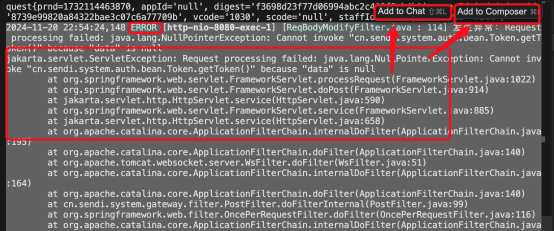
2. 运行错误
程序运行过程中遇到报错了,此时选中报错日志,然后选中区域右上角会出现
“add to chat”、”add to composor” 两个按钮,点击任何一个都会将当前选中内容作为一个相关上下文出现在 chat 或者 composor 中
3. 通过对话开发新的需求代码
以上技巧相对零散,可能都只____是____在局部使用,如果面对新的需求开发,如何让大模型为我们写代码呢?
为了可以让大模型从头开始帮我们完整地写一个新的需求,需要让他明白我们的需求,这个中间必然会出现理解不到位的时候,此时需要反复的迭代修改。
相信使用过大模型写实际项目的同事都领会过,有时需求可能并不复杂,但是让它调整到恰好适配我们实际项目环境(比如各种比较个性化的项目配置)就很麻烦,提示一次,修改一个小地方,再提示一次,再修改一个小地方,反复来回,感觉自己上手写更快速了,效率悖论隐约可见~
3.1 结构化的提示词
要想使大模型尽可能准确给出符合我们需求的结果,关键在于提示词编写得足够准确和详细恰当
由于我们需要的代码结果有很大幅度包含很多业务相关细节,同时整个项目使用的架构、依赖组件也有一定的要求,如果只是简单的寥寥数语,没有足够详细的说明,大模型大概率会根据自己训练时遇到的样本材料给出结果。但是如果每次交互都需要编写大段大段的文字,可能也会很累,觉得还不如自己写代码好了。
所以,此时,我们需要将提示词中常用的文字抽离出来成为一个有针对性的文档,比如用到的第三方依赖组件/技术、项目的内不同组件之间的交互/协作组织方式、开发规范、代码文件结构规定、外部数据存储方式、开发流程等相对固定的信息,在项目下新建目录存放这些文档,然后后续在进行新的需求任务开发时,每次都将这些文档作为项目上下文信息一并提交给大模型,让他在理解需求之后按照这些规范给我们生成,这样,大概率出来就是我们想要的结果了。这样就不用每次都写很多的文字,出来的结果也具有较高的统一性,比较好维护。
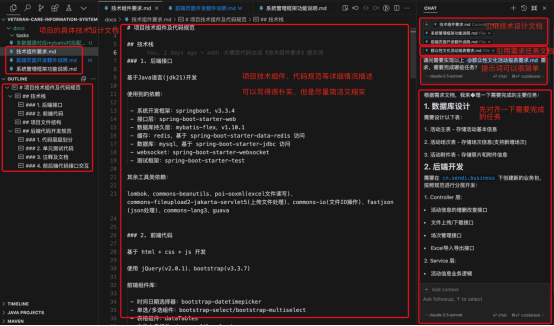
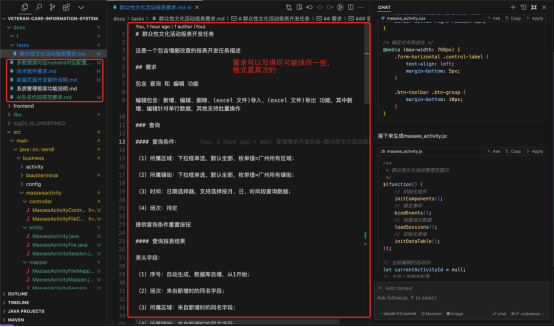
在项目实际开发业务需求前编写一定的技术、项目定义的基础文档可能会花费一定的时间,不过这些文档只需要在项目开始时编写一次(后续可能会修改更新),后续可以反复使用
整理的需求文档也可以在后续因为调整需要重新生成代码的过程中被反复复用
积累下来的这些文档相当于对整体项目有了一个比较详细的描述,在后续维护、交接的过程中会方便很多,直接交接一个代码仓库就完成很多事了
3.2 代码生成前的任务拆分
除了技术上的细节信息,在开发需求的时候,也可以尽量将需求任务按照逻辑进行一定的拆分,如果一开始对于任务拆分没有太好的思路,可以向大模型提问,让他帮我们整理思路,如果反馈的结果跟我们的理解有偏差,可以逐步调整,直至大模型给出的思路符合需求预期。

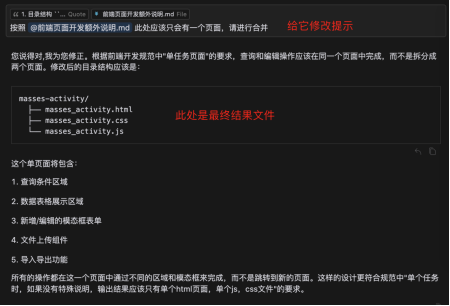
此时的交互还停留在文字版本的思路上,并不是直接生成代码。先让大模型拆分任务,也相当于跟大模型在对齐思路,避免在它生成结果时天马行空发挥,然后再一遍又一遍的阅读它的代码进行调整,面向自然语言对齐思路相对于面向最终代码对齐思路可能会更加容易一些。
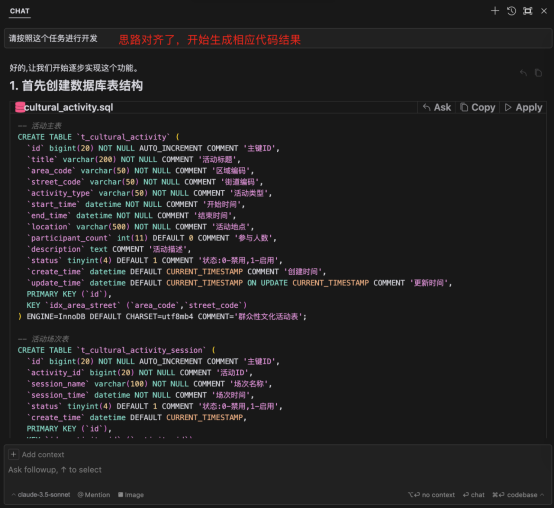
3.3 检验大模型输出结果:测试
大模型生成的代码有一定的概率会出错,有可能是技术上的,也可能是业务逻辑的理解错误,所以尤其是对于业务逻辑比较复杂的场景,加上一定的测试手段可以比较快速地帮我们发现这些错误。
让大模型先生成测试,然后面向测试来生成符合需求的代码,这样可以用机器来测试检验生成的代码可靠性,效率会高很多。


